
food maps
This is a write-up of a small tool that scrapes a graph of related dishes, according to the see also section of Wikipedia. I made it a couple of years ago for a project with the Knowledge Futures Group, along with Favour Kelvin, who was doing an internship with us at the time. I’ve revisited it a couple of times since, including re-doing the seeding stage and improving the filtering. The code for this project is here, which also contains a JSON dump of the graph that you can import into a neo4j instance at home.
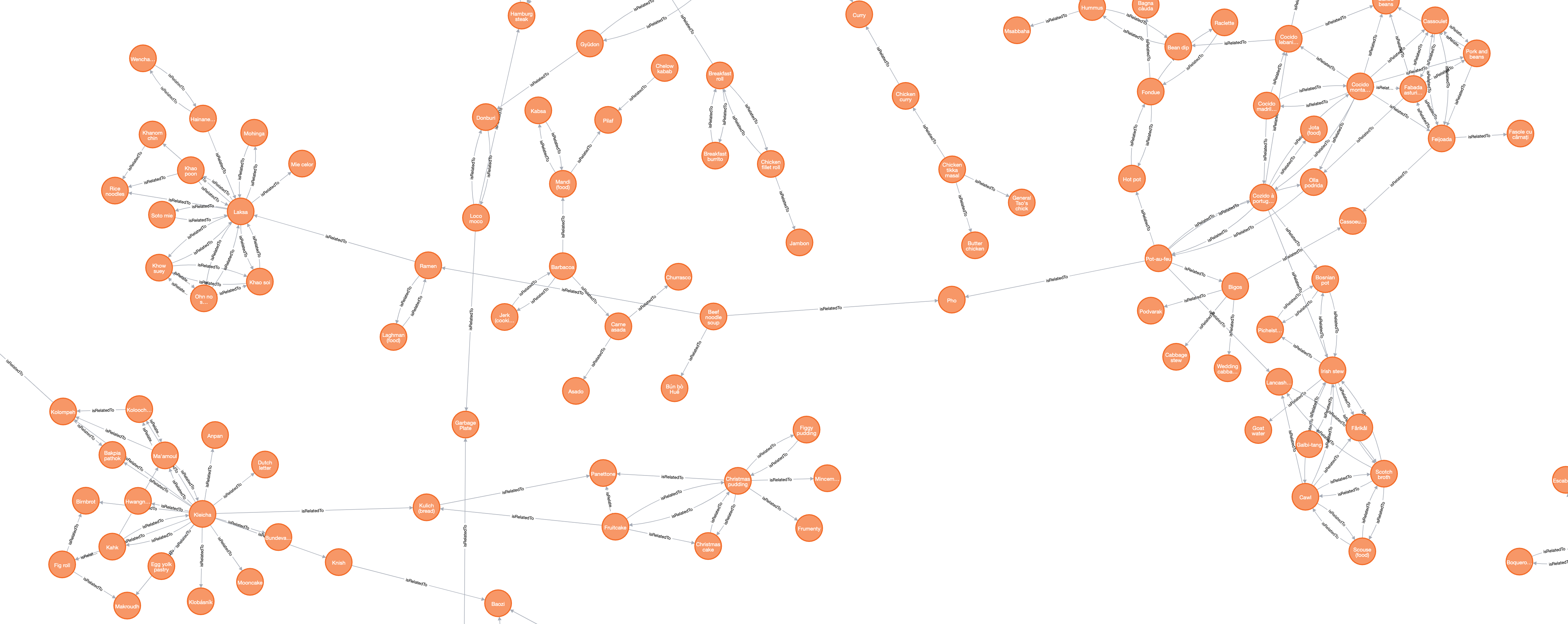 a small section of linked dishes in the graph, including clusters of stuffed pastries and noodle soups, fading into sandwiches and stews
a small section of linked dishes in the graph, including clusters of stuffed pastries and noodle soups, fading into sandwiches and stews
dishes vs recipes
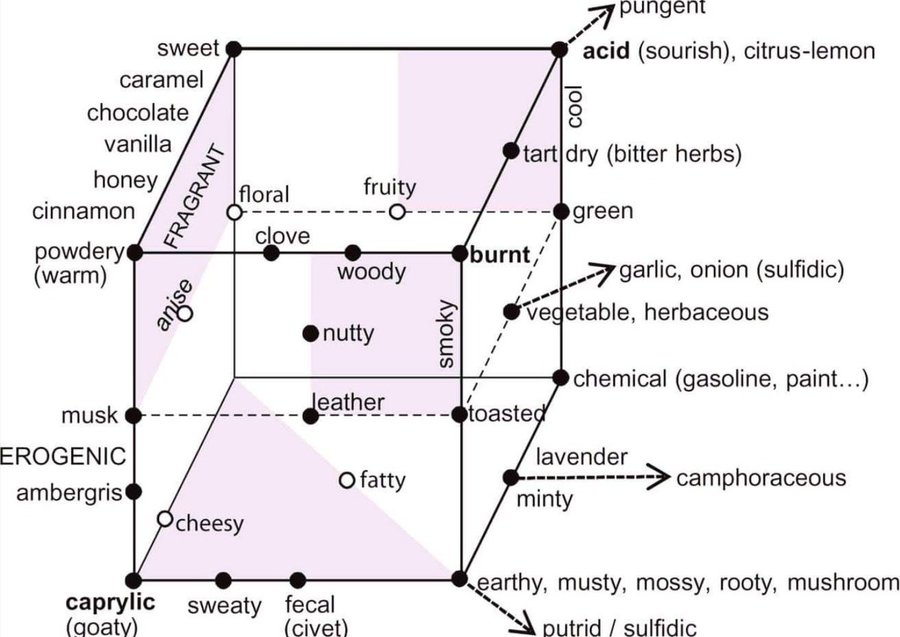 a spatial map of flavours (source unknown)
a spatial map of flavours (source unknown)
This project came out of a piece of consulting work around the design of ‘expert coding languages’ for cooking – the idea that, instead of being discrete entities, recipes were more like paths to particular points in a larger latent spacea term from machine learning, ‘latent space’ could be paraphrased as a high dimensional ‘space of possibility’, within which certain points are known, but assumed to be contained within a much larger continuous space. For example – what transformations separate a chewy cookie from a crumbly one? and what’s in the middle?. By changing aspects of the recipe – cooking time, amount of butter, temperature – you could end up in a different point in the space, and by the same token you could work backward. During the research stages of the project I got very interested in different ontologies for food (I’ve written about this collection here).
Part of the reason I like these is there’s something very deeply subjective about them – which gets interesting as soon as you start to try and do things with computers. In the end, the project itself became already-too-vast even within the smaller use-case, though I think the idea is still pretty interesting.
As well as collecting ontologies (and getting obsessed with industrial food texture modification manuals), I started to sketch out my own maps. I found this idea of a continuous latent space of food (just change the dials and you change the recipe into something inbetween) both deeply exciting, and also lacking.In the years since this project, I came across a really beautiful exploration of this tension (within the context of fonts!) in Douglas Hofstader’s fantastic essay Metafont, Metamathematics and Metaphysics
I thought dishes did a good job of articulating this issue: discrete things that couldn’t be easily faded between in a continuous manner. After all, what does it mean to mark a point halfway between a blood sausage and a kimchi stew? Below is an early sketch of a schema trying to map out these different culinary relationships:
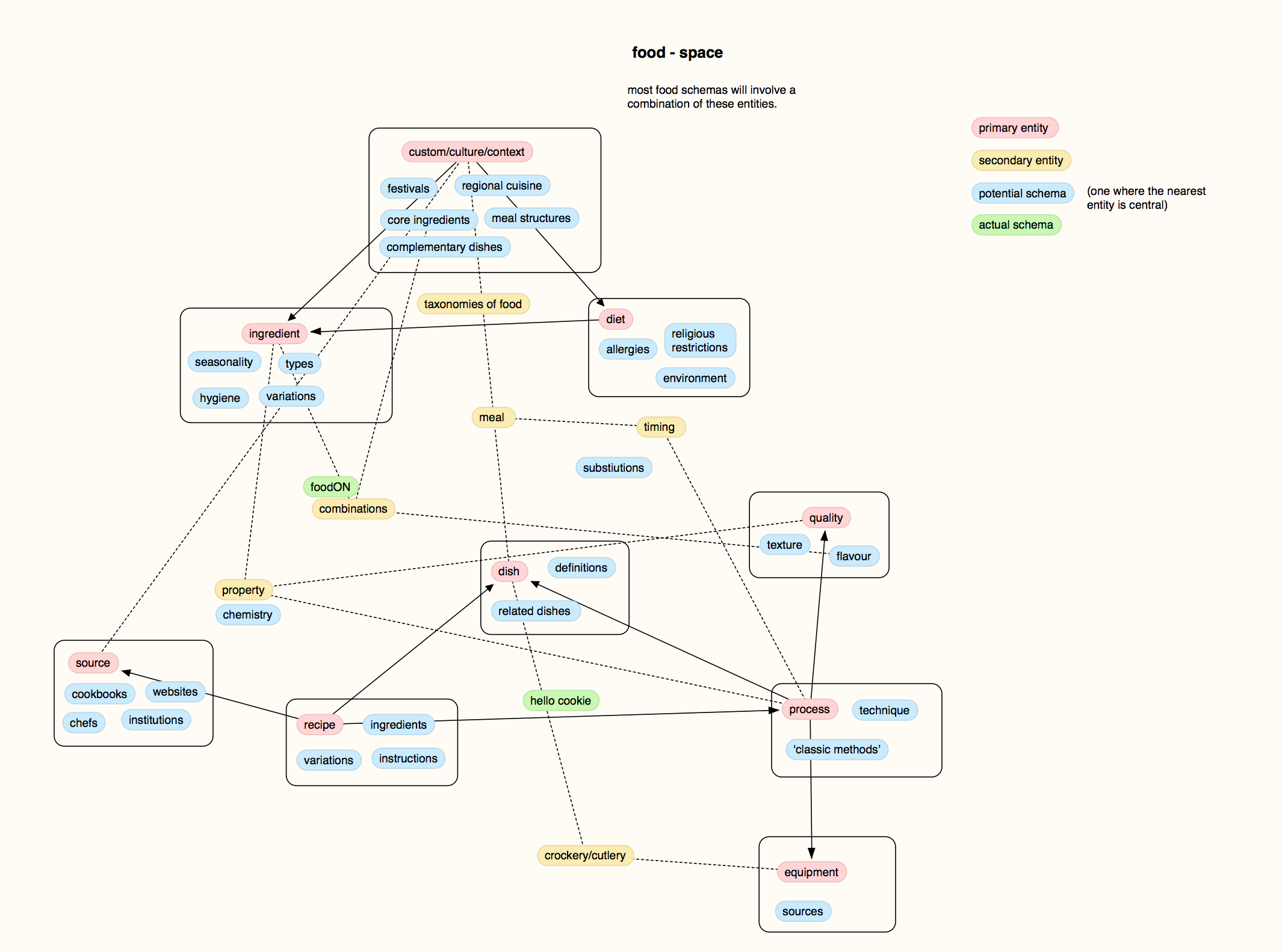
It felt important to have ‘dish’ be distinct from ‘recipe’. I think of a recipe as an instance of an instruction-set, that captures how to make a dish (named or unnamed)I feel like there’s also a continuum of how ‘dish-like’ a recipe is – though even recipes which don’t start out pointing to dishes can do, like drunk sandwiches that acquire a name after being perfected, while a dish is a concept, free to associate with other entites. A graph of dishes deals with overlapping but distinct: what other dishes, cuisines, holidays, meals, events, people, places or other practices are associated with this dish? What dishes exist in the world? How is a dish described?
The answer to the last question is surprisingly sticky if you don’t count recipes as a description of a dish, and it made me think about the way we articulate dishes in terms of their relationships to other foods (which I think is more broadly about being able to express something most succinctly in terms of a shared experience). It’s certainly not a complete description and it’s also highly subjective – but moreso than most I think descriptions of dishes are necessarily subjective, unlike an instance of a recipe, which can also be precise.
Wikipedia’s ‘see also’ section felt like a good place to start with this as it’s so ambiguous, and there are no hard rules – things can be related as they have similar ingredients, a similar form factor and/or textural qualities, or are made using a similar process – it seems like editors mostly go on vibe.
the scraper
 the crawler (affectionately known as ‘the worm’) crawling through recipes
the crawler (affectionately known as ‘the worm’) crawling through recipes
The scraper starts on a page for a particular dish, and extracts links from the ‘See Also’ section, which contains links to other pages the editor thinks are related. These pages might be other dishes (we want these!) but could also be random things. For example, here’s the See Also section for Borscht:

We want our crawler to visit shchi and cabbage soup, as these are both dishes, but we want it to skip the other links though I’m really taken with the strangely unpatriotic three grand soups
To decide which pages we are interested in knowing more about, the crawler goes through each link in the ‘See Also’ section of the page fetches all the categories that the page belongs to. If none of the category titles contain the any of the words ‘dishes’, ‘bread’, ‘dessert’, ‘pudding’, ‘pastries’ (pluralised because of the way categories are worded Initially I actually used the singular ‘dish’ but then had the issue of collecting multiple pages with categories containing the word ‘Swedish’, which also has ‘dish’ as a substring, and had to kill the crawler as it attempted to index every member of Sweden’s parliament… (second footnote – I wrote the original tool before learning regular expressions)) then the page is skipped as it’s probably not primarily a page about a food. If the page does seem to be a dish, then the scraper creates a relationship between it and the page it was linked from, and adds it to a list of pages to crawl next. For example, here are the categories for shchi:

When a page is crawled, or if it’s found to contain no relevant categories, it’s added to an array of pages to skip, as it’s already been scraped. Eventually, the crawler runs out of paths its already been down, and grinds to a halt (current endpoint, itself very funny, is Jubilee chicken)
The crawler also scrapes the categories associated with the page it’s crawling, and adds them to the graph too. This is nice later on, as you get to see which categories have the most overlap in terms of dishes.
seeding
 the wikipedia list of national dishes
the wikipedia list of national dishes
In order to crawl a good section of the graph, we had to come up with a set of ‘seed dishes’ that would spread the crawler initially over a range of different cuisines and types of food, rather than just trying to go from a single start point. To get a good range of cuisines, we started with the Wikipedia Category of National Dishes, plus a set of random links from List of Desserts to balance a bias in national dishes toward savory foods. (I might have over-compensated for this, however, as the final graph ended up quite dessert-y).
filtering unhelpful categories
I wanted to include a broader range of categories in the graph than was used to filter pages – e.g. a page probably doesn’t contain a dish if it doesn’t belong to any categories containing the word ‘dish’, but there might be categories relevant to its culinary qualities (like ‘pickle’, ‘pastry’, ‘cookie’) that still contain useful information for clustering. As such, the filtering involved iteratively picking out terms common to ‘wikipedia metadata’ and other less useful categories.
limitations
There are a number of obvious limitations to this – namely, this is only working on english-language Wikipedia, which probably has regional biases as to what dishes (and links between dishes) are included. There’s also the major issue that links in the main text don’t get included in See Also – potentially missing loads of important links. It’s also not certain whether this method gets all the pages marked ‘dish’ – I haven’t come up with a good metric to determine what proportion of ‘dish’ articles are successfully indexed by the crawler, because there’s no singular category ‘dish’ on Wikipedia. I think the way to do this would be something like:
- filter all categories by the category criteria used
- for each of these categories, get the list of categoryMembers
- remove duplicates and count, potentially use this to seed the next round
I’ve also been fairly un-systematic with the script – earlier versions allowed pages that belonged to categories involving ‘bread’, which I took out as there were a lot of bready pages that weren’t really dishes, but am now considering putting back in. (cake is also another possibility)
exploring the data
The Python script dumps all the relationships between pages and categories into a big Neo4j graph database instance, using the py-neo4j package. Dishes that are linked to one another are defined by an isRelatedTo link – and links from dishes to categories by hasCategory. The only node types are Dish and Category. Here’s a small subsection of the network, showing dishes and categories linked to pho and adjacent soups:
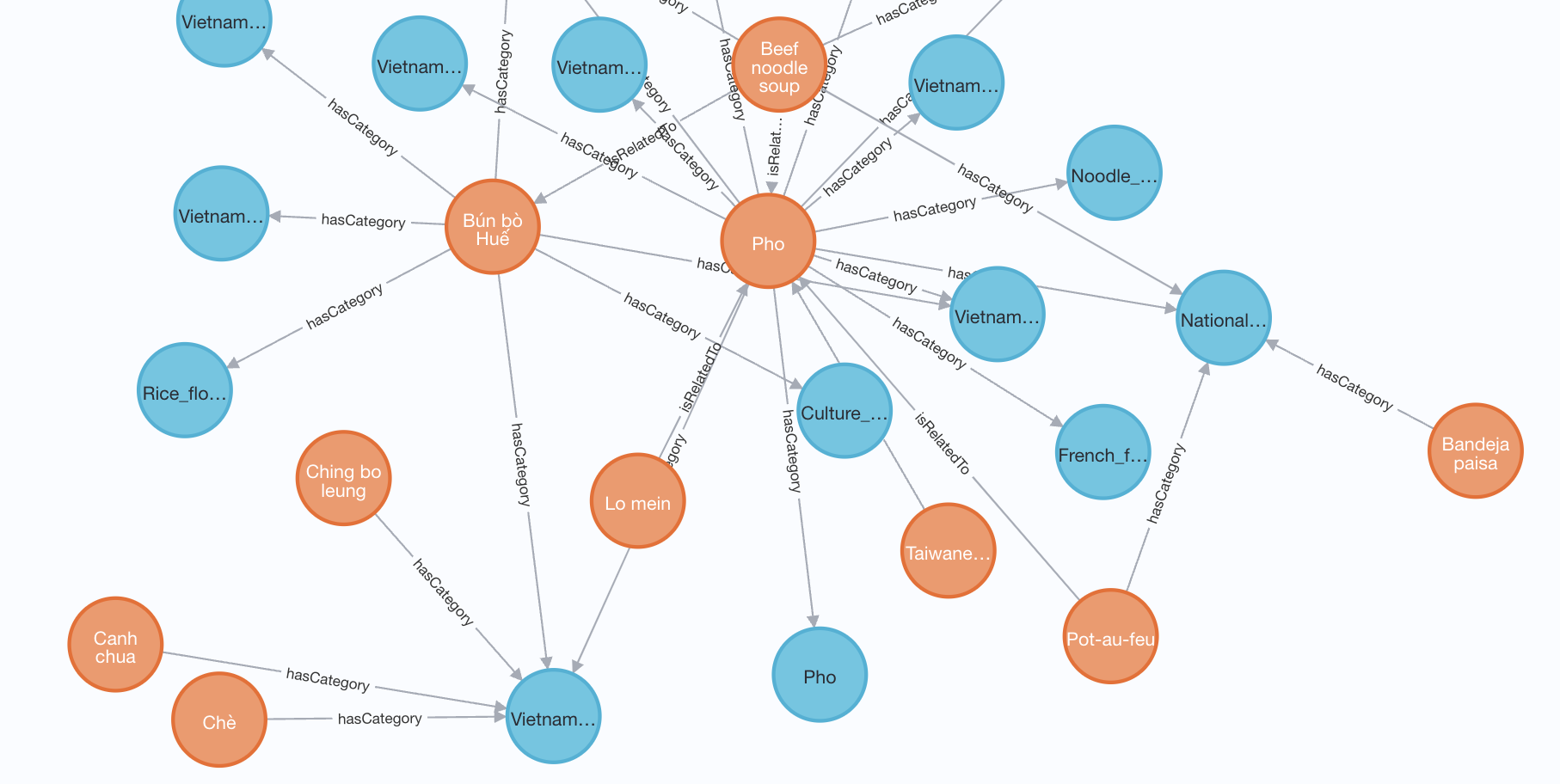
I found Neo4j’s desktop tool initially quite clunky, but after a while began to enjoy playing around with the data. Here’s a query in their Cypher query language that maps out a path (travelling only by related dishes, not categories) from Hummus to Turducken.the lack of arrows around the -[:isRelatedTo*]- part of the query is to allow the arrows to be taken in either direction: if you insist on them being unidirectional, the graph gets much harder to traverse, as not all pages that link a dish in the ‘see also’ section are linked back by it… in a way this is also a fun separate analysis to run
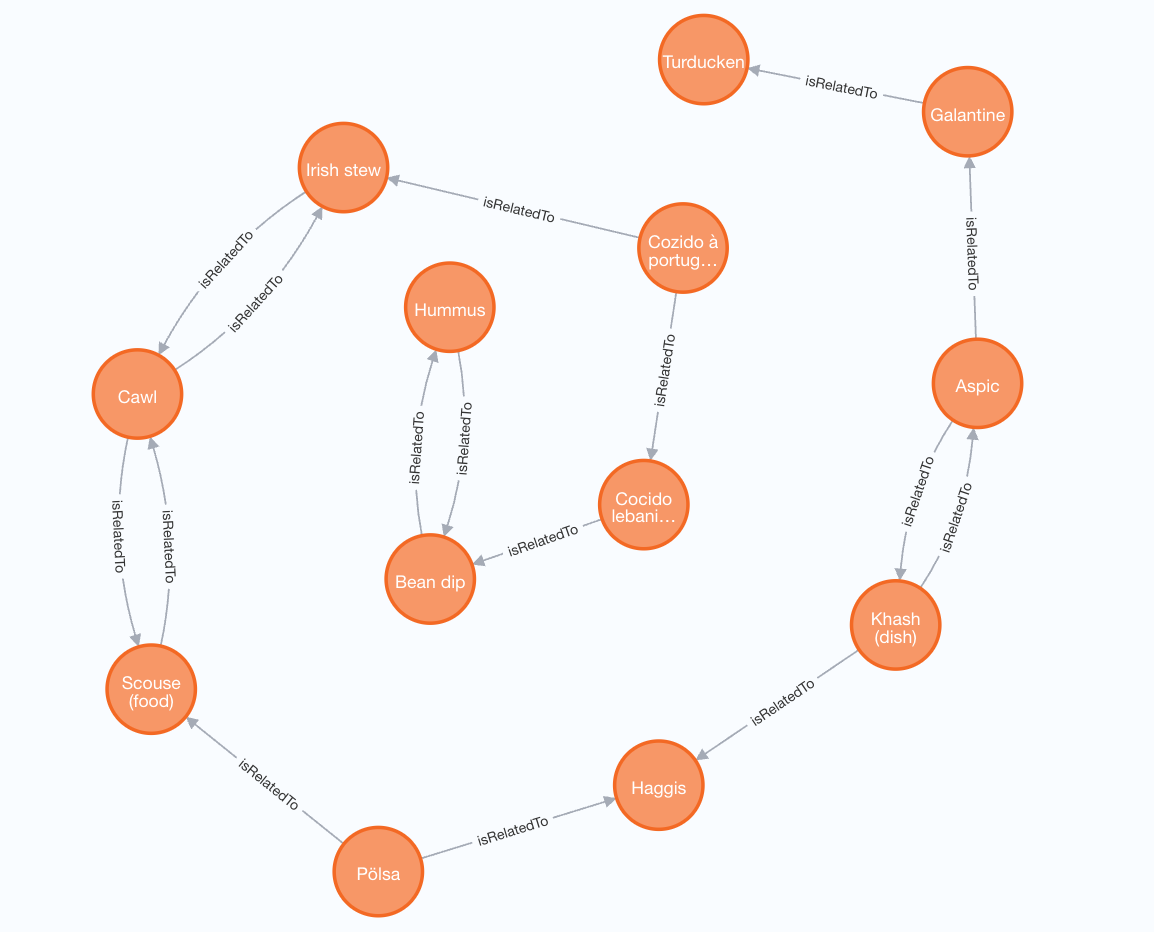
match p=shortestPath( (k:Dish {name: "Pizza"})-[:isRelatedTo*]-(a:Dish {name: "Banana cake"}) ) return p
And here is the resultant graph. Note the ‘offal corridor’ of associations leading us through staple dishes into stuffed monstrosoties:

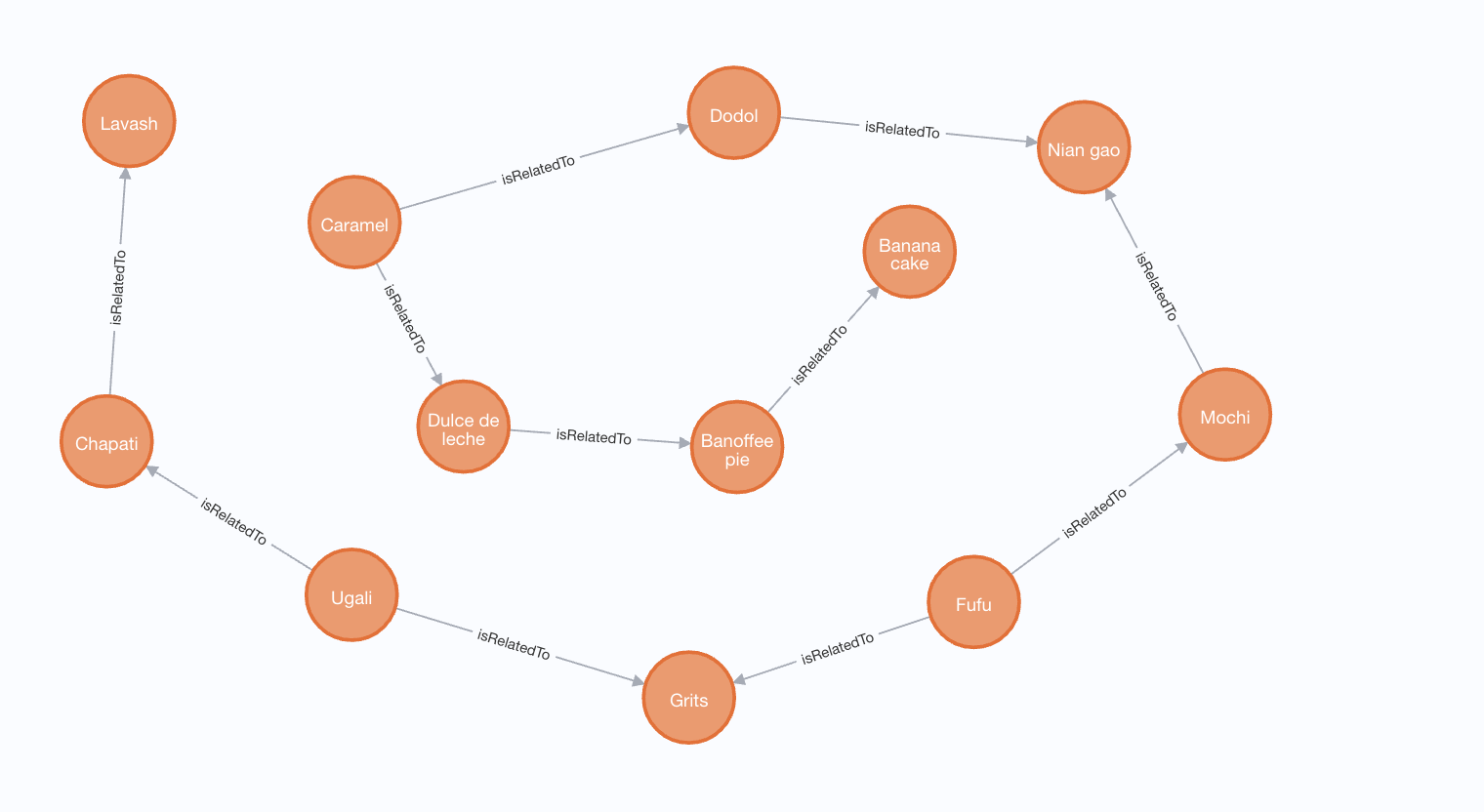
Here’s another, from Banana Cake to Lavash:
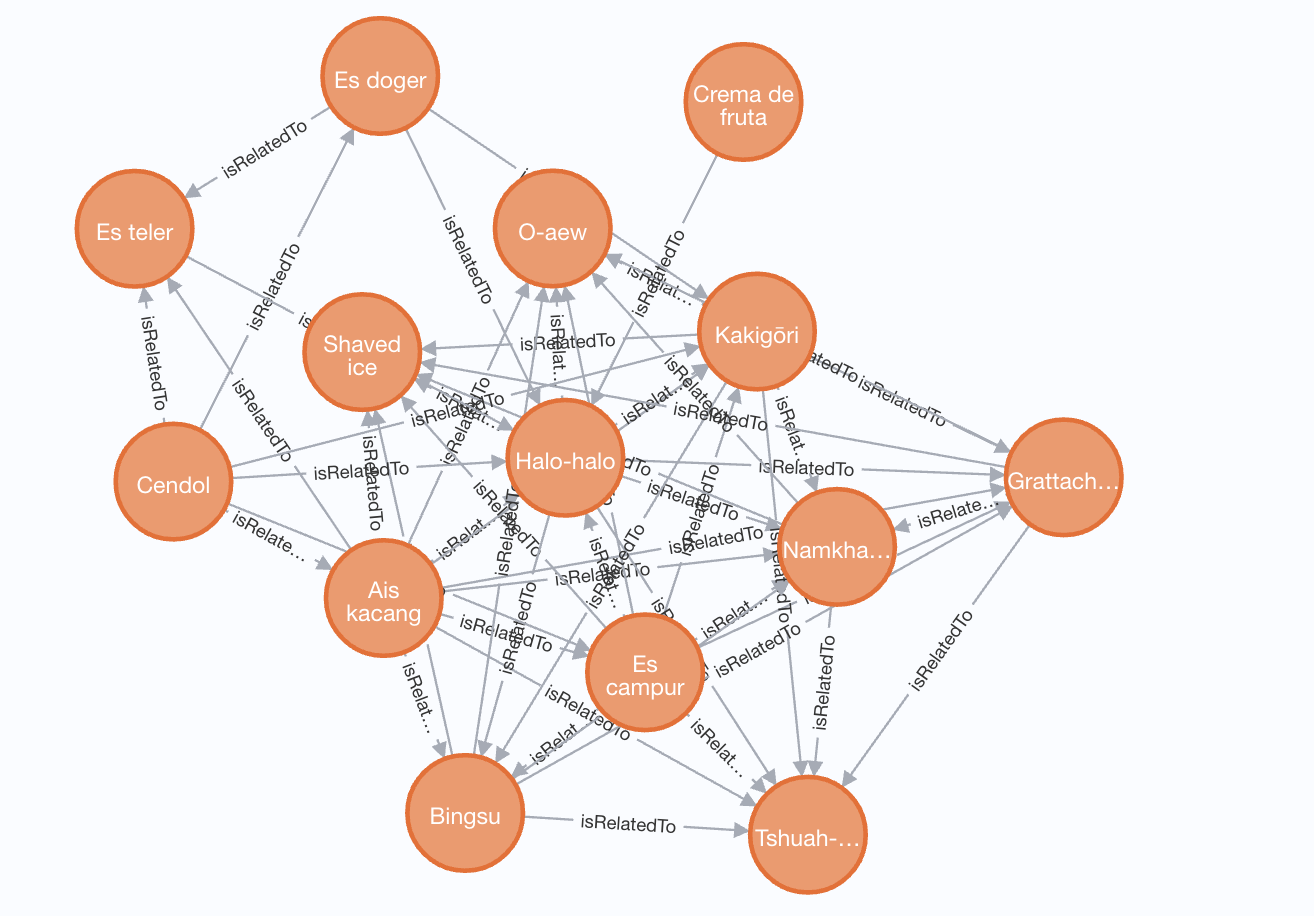 a tightly related cluster around halo-halo
a tightly related cluster around halo-halo
One thing I like about this is the train of associations: they flip between flavour, technique, form, cuisine and culture, forming loose chains of association. You start to see the same ‘nodal’ pages a lot that bridge between different form factors of food – Khachapuri, for example, provides an important bridge between stuffed dishes and flatbreads. Another common node that acts as a cultural bridge is fusion cuisine, for example the Hawaiian noodle dish Saimin crops up a lot in chains between European and East Asian cuisines.
You also develop a sense for parts of Wikipedia where the dishes are highly clustered – like this tight-knit group around Halo-Halo, or within Indonesian cuisine, itself maybe an articulation of the great degree of mixing and cross-influence within e.g. east asian desserts.
Because the categories are also scraped, you can do nice things like this:
match (n:Dish)-[r:hasCategory]->(c where lower(c.name) contains "pastries")
return n
This gets all the dishes that have a category name containing the string ‘pastries’, and threads them together. It’s so big! I thought it was nice to put the whole thing laid out (there’s more writing after).

I really like seeing which things get connected (and by what!) and which are left unconnected, or small islands at the edge of the graph (like the French separatist patisserie corner! macaron -> petits fours).
getting from A to B
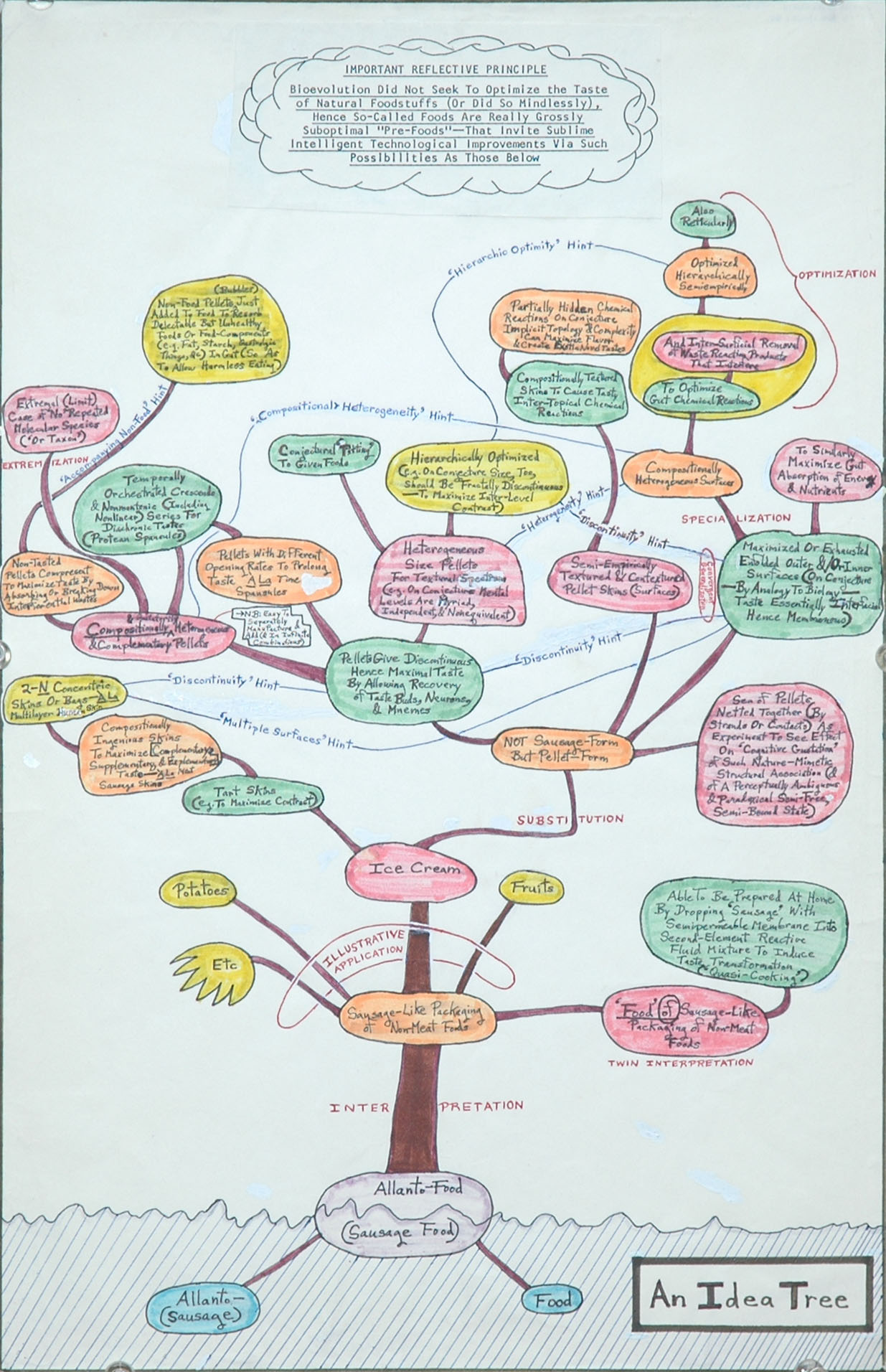 a small version of Patrick Gunkel’s An Idea Tree (full size here)
a small version of Patrick Gunkel’s An Idea Tree (full size here)
{kind=link}
A big influence on this project is the work of Patrick Gunkel, founder and core proponent of the field of ideonomy– the science of ideas. Many years ago my friend SJ introduced me to Gunkel’s work, via the masterpiece ‘An Idea Tree’ (small version right), which takes the initial idea of allanto (sausage-like) foods, and follows multiple ‘hints’ and ‘interpretations’ to theorise, for example, the appearence of mochi ice cream some decades before its introduction into Gunkel’s native Texas.
This tree of sausage-inspired innovation follows a surprisingly similar set of jumps to the map of dishes, albeit with the latter feeling less self-consciously ‘innovative’. The forking, folding path – the ‘staple’ hint, the ‘deep frying’ hint – unfolds layers of different ideas and techniques that have built up between cuisines over time.
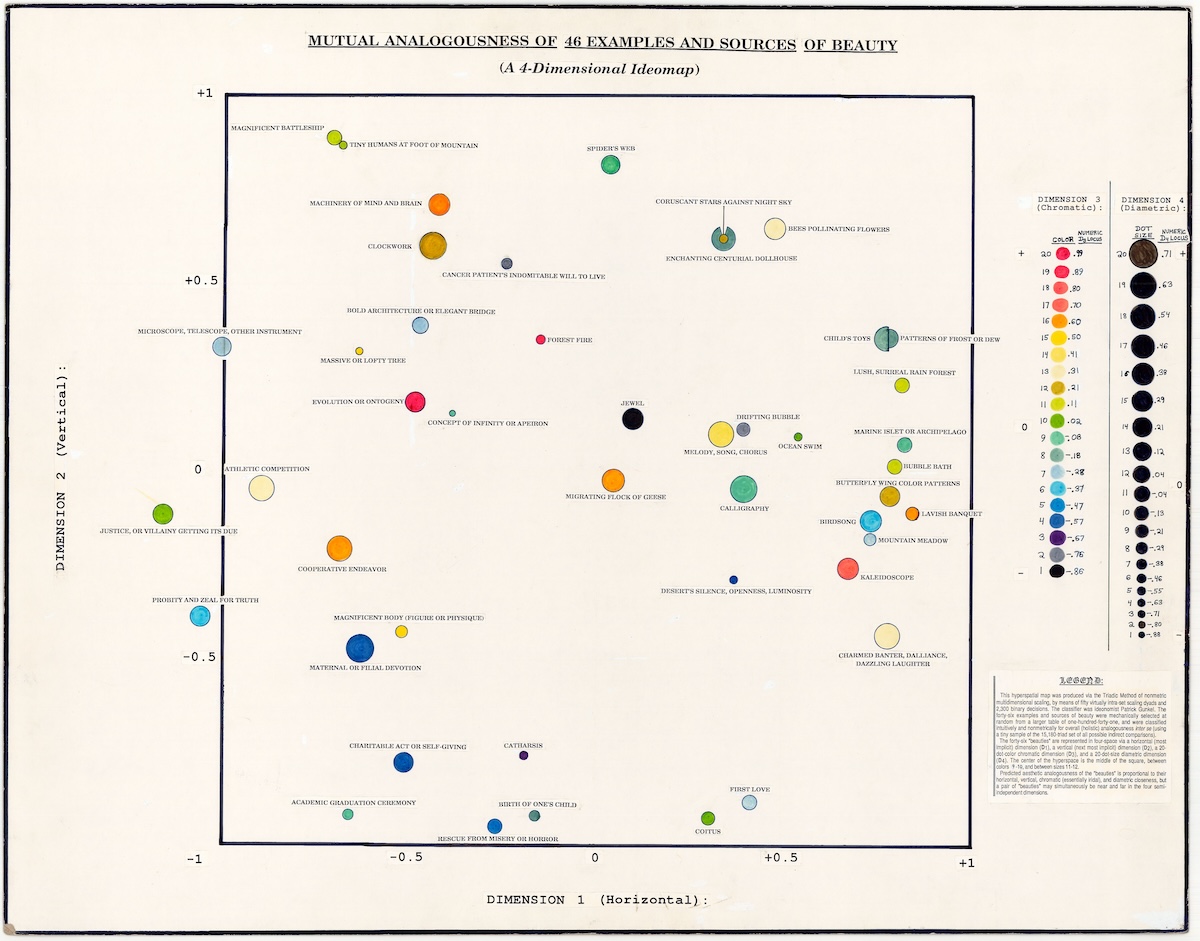
I’m a big admirer of Gunkel’s broader work for his interest in applying extraordinarily thorough, scientific and detailed methods to further the understanding of fleeting, subjective and slippery ideas. His articulations don’t pin them down, so much as flesh them out – expanding their descriptive possibilities by searching for many definitions within them. It’s a form of inquiry that feels genuinely inquisitive, and is also extremely funny – a couple of my other favourites are his map of mutual analogousness of ‘Examples and Sources of Beauty’, and another tree ‘Illusions re: A Stone’.
{kind=link}
Without wanting to overstate here, I think this is quite a good example of what science should be for – the use of the constraint of objectivity as a flexible tool to expand the kind of questions that we’re able to ask about human endeavours, to expand our imaginitive landscape. Gunkel’s method is extremely fastidious and thorough‘gunkeling’ is a classic example of something that looks really easy until you try it, and takes abstract things very seriously, delighting in the non-obvious links that can be made between different ideas.